
by Javantea
May 12, 2009
Hooray!
The Twitter Language AI is ready to be used! How do you use it? Type a word
into the input box, then click "Search". This will search Twitter for that
word. It will return the last 15 results and histogram all the words it finds.
This is very simple functionality, right? Why would someone want a histogram of
words spoken on a topic? For one, market research. If you know the word that
people associate with your brand or topic, you can market it using their words.
Yowch, that's almost like advertising, isn't it? Yup. The actual original
purpose for this was to learn foreign languages by translating the most common
words first (similar to my Japanese Language AI). The second interesting thing
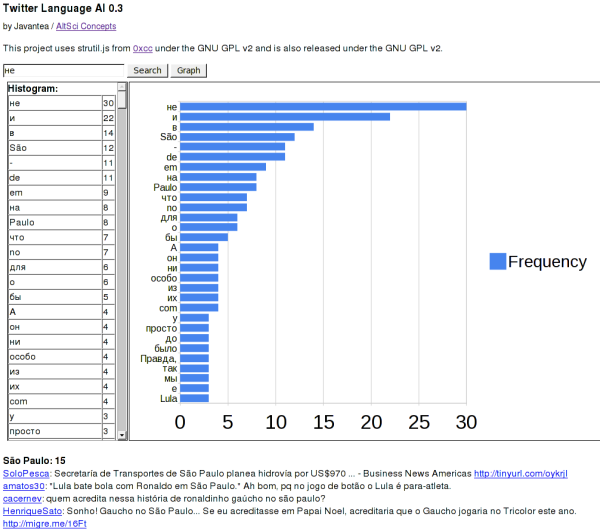
to do with the Twitter Language AI is to click the "Graph" button. This will
take the data in the left and graph it on the right as shown in the image.
This is really interesting and useful for scientists who don't want to import
the data into a spreadsheet just to graph it. It uses the Google Visualization
API and sends no data to Google (just your IP address and HTTP headers) to draw
this, which is pretty cool.
Click the image above to use the Twitter Language AI.
A few Javascript workarounds were required for my Twitter Language AI to finally work. I'm glad that I wrote it in Javascript because it reminds me how sheltered I am when I write a ton of Unicode, ASCII, ISO-8859-1 encoding junk so that my program "just works". You see there are encoding issues that are bound to occur when you assume that everyone else is doing things correctly. In Javascript, however it doesn't even act sane in the encoding front. So to fix it I added a utility script strutil.js from 0xcc to encode and decode my strings. Since it is released under the GNU GPL v2, I am also releasing my code under the GNU GPL v2. I would have anyway but this forces my hand for the moment which is a good thing. I intend to remove strutil.js when possible, but not for a while. If your project involves Javascript and unicode (it should!), strutil.js makes it easy to encode and decode your data on its way to a web service like search.twitter.com.
The second Javascript workaround I found was that Regex doesn't like unicode
very well, but that I could reverse the regex to make it work. You see, when
this regex /[\w]+/g sees a unicode ã, it considers it a
non-word character because it's not ascii. On the other hand, the regex
/[^\s]+/g sees everything except space, newline, and tab as
characters. We are left with various non-word characters like quote,
apostraphe, comma, period, @, slash, backslash, colon, etc but that is actually
pretty useful.
What I end up with is a beautiful histogram of a language which can be added upon until Twitter stops letting us use their service (their limit is ~1000 requests).
You might be wondering, what does this have to do with Artificial Intelligence? The same question came up after I released my Japanese Spam AI last fall. AI is defined by performing functions that are associated with human intelligence [3]. This is achieved through a learning technique that allows a computer to act efficiently. These two projects allow a human to learn a foreign language in the most efficient way: from the most used words to the least used words. Normally a person goes to an instructor and expects them to teach words that are of immediate use first. However instructors are often inefficient by requiring students to memorize words that are not as useful as more common words. Thus these two projects aim to become the most efficient way to learn a foreign language. Eventually these may replace other language learning methods. I also have a secondary goal to create a natural language processor with a similar method, which is more commonly considered to be artificial intelligence.
As an added bonus I am going to write three equations I wrote that apply to Artificial Intelligence, natural language processing (NLP), and a random other project that I've spent some time on recently. The first equation is the likelyhood of a Kaminsky that I found in a semi-random building in downtown Seattle is the Dan Kaminsky. This may seem creepy or weird, but I thought it was actually enlightening. If we knew that N Kaminsky's lived in Seattle, we could simply say the odds are 1 in N. But the Yellow Pages are not accurate, considering there are only 3 listed and none are Dan. Instead, let's calculate the likelihood of finding someone who has the same last name. For common last names like Smith, it's incredibly high probability of finding a someone with the same last name. But with so few results in the Yellow pages, we can assume that it isn't that common a last name. I will use a system that I use to calculate the strength of passwords to find the likeliness of finding a Kaminsky. Unlike most passwords though, Kaminsky is not random, we cannot say that it is 26^8 = 2.09e+11. Instead, I am going to use a bigram and trigram method. The bigram "Ka" is fairly uncommon, so I give it a worth of 40. The bigram "mi" is also uncommon, so I give it a worth of 40. The unigram "n" is extremely common, so I give it a worth of 5. The trigram "sky" is common because it's a last name postfix for a certain Scandinavian group of people, so I give it the worth 20. At this point, we just multiply the worths together to get the likelihood of the name popping up out of nowhere: 40*40*5*20 = 160000. But this number says what's the likeliness of me finding a Kaminsky anywhere. What about in Seattle? If we assume the likeliness of finding a Kaminsky equal over the population of the world (quite incorrect), we can say that metro Seattle is 1M/6B, so there should be 160000 * (1/6000) = 26.67 Kaminsky's in Seattle. Thus our final answer is that the likeliness of me randomly finding Dan Kaminsky's apartment is 1:26.67. Have I made any obvious mistakes with this calculation? Of course, but it's at least within an order of magnitude or two. =)
The second equation is the amount of training required to teach a decent natural language parser all of addition between two numbers between 0 and 5. Of course this doesn't make sense, why would you want to teach an AI to add? The reason of course is to learn what every kindergartener learns. If we can learn what a 5-year-old can learn in 1 day, we can learn what a 6-year-old can learn in less than a year. So let's get to it. How many combinations exist in this?
A + B = C [ ] + [ ] = [ ]
Similar to the Dan Kaminsky equation above, we can see that the "worth" of the first variable A is 6 because A can be any number between 0 and 5 inclusive. The "worth" of the second variable B is also 6 for the same reason. The third variable is different of course because it can be any number between 0 and 10. Thus the "worth" of C is 11. We can then multiply these three worths to get the answer: worth(A) * worth(B) * worth(C) = 6*6*11 = 396. So if you are trying to teach a natural language parser basic arithmatic, you will have to spend 396 units of time to teach it. If your time investment is 30 seconds per equation, you will spend 3.3 hours teaching this NLP this simple thing. Of course, the NLP would not know 6+6 or even 5-1. But since we have algorithms that can do the training perfectly without any human intervention, you can teach an NLP all arithmatic basically for the cost of the computation. For example, putting 43 * 3.1415 into Python reveals the result 135.08450000000002 -- better than any 6-year-old who doesn't have a calculator.
What does this equation mean to NLP though? It means to teach a NLP a few sentences of 3 words that are very simple it takes hours. However, using a technique similar to those I employ above with the Twitter Language AI and the Japanese Spam AI, I will be able to teach my NLP millions of the most important sentences in the world with no work beyond the initial investment.
The third equation is rather controversial even though it looks initally very inert, but I hope you'll read it so that you can reap the benefit. When I was unemployed many years ago I didn't understand this nearly well enough and I wish I had calculated when I had so much free time.
Who cuts hair these days? Given: 2M people in the city Given: 30 minutes per hair cut Given: 1 haircuts per 2 weeks 2000000 * 0.5 hours / 2 weeks = 500000 hours per week Given: 40 hours per cutter per week 500000 hours per week / 40 hours per cutter per week = 12500 cutters in the city. 12500 / 2000000 = 0.625% of the city are haircutters.
This same equation can be done for any job. So long as you know the demand for a certain job, you can calculate the supply that the industry is willing to allow so that wages do not plummet.
What does this equation tell us? For each industry there is a nominal number of full time workers which grows and shrinks all the time but is naturally limited. If there are more workers than demand, wages plummet. If there is more demand than workers, wages skyrocket.
Does this equation make you angry? If so, I encourage you to write down why. May I ask what part of the equation you affect that can modify the outcome of the equation for your betterment.
Javantea out!
Permalink-
Leave a Reply




Comments: 0
Leave a reply »